Introduction to Machine Learning
Hello everyone! Artificial intelligence and machine learning may seem like complex topics, but they’re more accessible than you think. We’re going to pull back the curtain on AIML and explain the foundational principles in a way that’s easy to grasp. We’ll prove that, understanding these concepts is less about being a genius and more about simply seeing how things work.
Let’s start with the big question: So, what exactly is machine learning? Think of it this way: It’s a way to get computers to learn from data, get better over time, and make decisions without us having to write every single instruction. It’s like teaching a kid to ride a bike—you don’t give them a detailed manual on balance and steering. You just let them try, fall down, and learn from their mistakes. That’s what machine learning algorithms do with data. They analyze patterns and use them to make smart predictions.
You probably interact with ML more than you think. When Netflix recommends your next movie or Spotify creates a custom playlist just for you, that’s ML at work. It’s also the tech behind things like language translations on your phone or even self-driving cars. The world of AI is popping with cool new stuff. Did you hear about that wearable headset, AlterEgo, that lets you ‘speak’ without actually saying a word? It sits near your ear and jaw, picking up signals when you silently form words and converting them into text or commands. It’s a game-changer for people with speech impairments

Before we dive into the different types of ML, let’s take a step back and look at the bigger picture: the ML lifecycle. Think of it like a recipe for making a great dish. You can’t just throw all the ingredients in a bowl and hope for the best. You need a process. This lifecycle ensures that the models we build actually solve real problems and stay useful over time.
Here’s a quick breakdown of the steps:
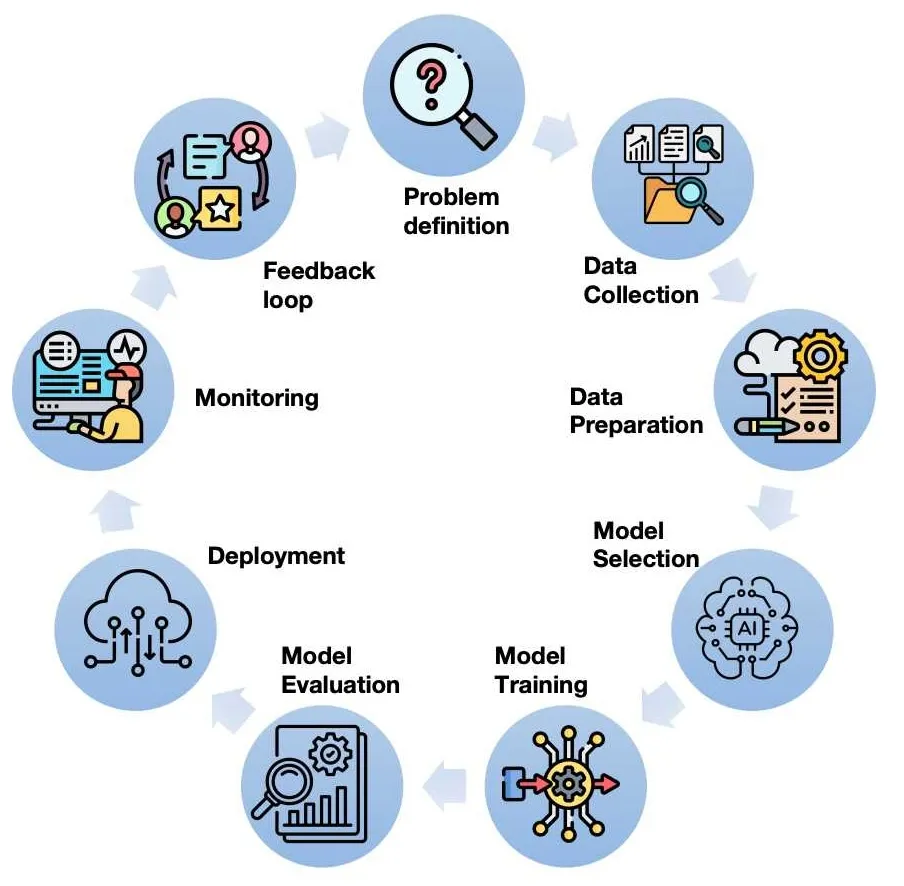
- Problem Definition: First, you have to know what you’re trying to solve. For example, ‘Can we predict which customers are about to leave us in the next three months?’.
- Data Collection: Next, you gather all the raw ingredients—the data. This is where you find the missing pieces and clean up any messes.
- Data Preparation: This is the ‘chopping and dicing’ stage. We clean the data and get it ready for the model to use. This is also where we do some exploring to understand what we’re working with.
- Model Selection: Now, we choose the right tool for the job. Do you need a hammer or a screwdriver? We pick the right algorithm based on the problem.
- Model Training: This is the main event! You feed the prepared data into the algorithm so it can learn patterns.
- Model Evaluation: After training, you check to see how well your model performed on data it’s never seen before. This is where you find out if your model is a genius or just good at memorizing.
- Deployment: Once you have a working model, you put it out into the real world.
- Monitoring & Maintenance: Your job isn’t done yet. You need to keep an eye on your model to make sure it’s still performing well as new data comes in.
- Feedback & Iteration: The final step is to collect feedback and use it to make your model even better. It’s a continuous loop of learning!”
Now, let’s get back to the main types of ML and add in those details.
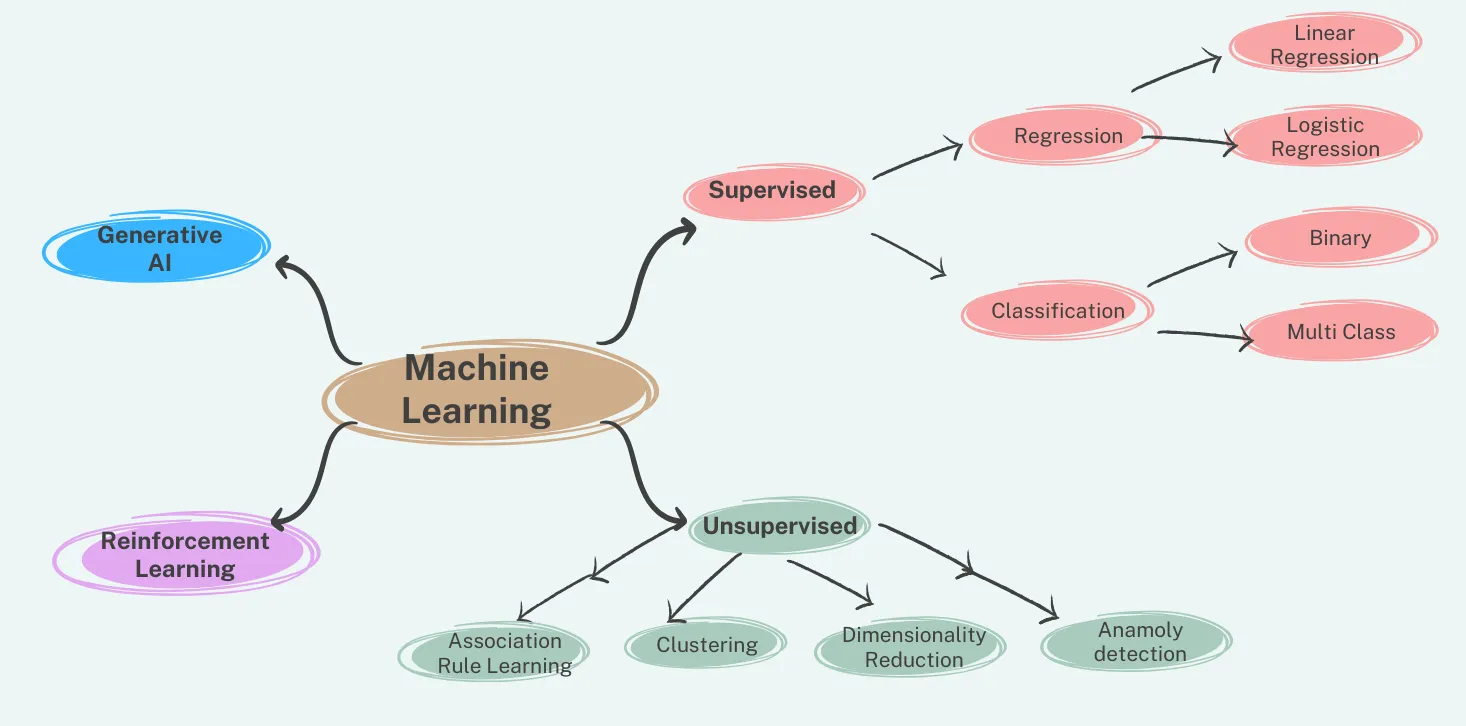
First up, Supervised Learning, the ‘I’ll show you how it’s done’ method. We give the model a labeled dataset—data with both the inputs and the correct answers. The model learns from this and makes predictions on new data. This is divided into two main categories:
- Classification: This is used when the outcome is a category. Think of it as a sorting problem. It can be a binary classification, which has only two outcomes, like ‘spam or not spam’. Or it can be a multi-class classification, which has more than two outcomes, like predicting the breed of a dog.
- Regression: This is for when you need to predict a specific, continuous number, like predicting a student’s test score based on the number of hours they studied.”
Next, we have Unsupervised Learning, the ‘figure it out yourself’ method. Here, the model gets unlabelled data and has to find the patterns on its own. This is broken down further:
- Clustering: This is all about grouping similar data points together. A real-world example is grouping customers by their purchasing behaviour, like ‘high spenders’ or ‘low spenders’.
- Dimensionality Reduction: This sounds complicated, but it just means simplifying a lot of data while keeping the most important information. It’s like taking a super-detailed photo and making it a simple thumbnail, so you can get the big picture.
- Association Rule Mining: This is for finding interesting relationships between variables in a large set of data, like what products are often bought together. Anomaly Detection: This is about finding the weirdo of the group—the rare or unusual patterns that don’t fit in. This is how a credit card company might spot a fraudulent transaction.”
Finally, there’s Reinforcement Learning. This one is a bit like training a pet. The model learns by interacting with its environment and getting rewards for good behaviour and penalties for bad behavior. The goal is to maximize the rewards. A classic example is a robot learning to navigate a maze. It bumps into walls, gets a penalty, and learns to avoid them, eventually finding its way to the reward at the end.
And then there’s the rockstar of the moment, Generative AI. This is the one that creates brand new content from user input. We’re talking about things like creating unique images, writing music, or even generating a joke. It’s also what’s behind the scenes of tools like ChatGPT and Gemini.
Now that we’ve covered the basics, you might be wondering, ‘What’s next?’ For the rest of this course, we’re going to roll up our sleeves and dive into the exciting worlds of Supervised and Unsupervised Learning. But before we jump into creating some cool models, we need to talk about the most important part of any AIML project: the building blocks.
In the real world, a huge chunk of an AIML project—over 70% of the time—is spent on something called Exploratory Data Analysis, or EDA. Getting your data right is like getting the foundation of a house right. Without a solid foundation, no matter how beautiful your house is, it’s not going to stand. The same goes for your models—they won’t do the right job if your data isn’t prepared properly.
So, in our very next blog, we’ll tackle a super important topic: the essential Python modules you’ll need for AIML. We’ll focus only on what’s essential so you’ll be ready for some exciting, hands-on exercises! Stay tuned, you won’t want to miss it!